Explain Information Retrieval. Also, Basic Measures for Text Retrieval.
Information Retrieval
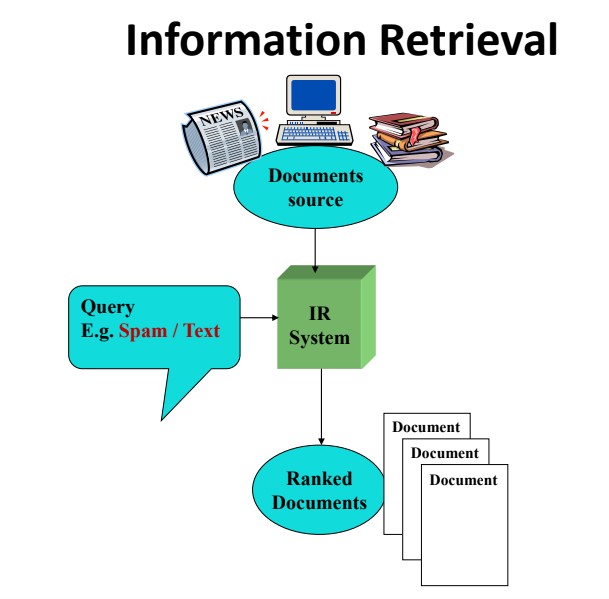
- Information retrieval deals with the retrieval of information from a large number of text-based documents.
- Examples of information retrieval systems include − Online Library catalog systems, Online Document Management Systems, Web Search Systems, etc.
- The main problem is an information retrieval system is to locate relevant documents in a document collection based on a user's query. This kind of user's query consists of some keywords describing an information need. In such search problems, the user takes an initiative to pull relevant information out from a collection. This is appropriate when the user has an ad-hoc information need, i.e., a short-term need. But if the user has a long-term information need, then the retrieval system can also take the initiative to push any newly arrived information item to the user.
- This kind of access to information is called Information Filtering. And the corresponding systems are known as Filtering Systems or Recommender Systems.
Basic Measures for Text Retrieval
We need to check the accuracy of a system when it retrieves a number of documents on the basis of the user's input. Let the set of documents relevant to a query be denoted as {Relevant} and the set of the retrieved documents as {Retrieved}. The set of documents that are relevant and retrieved can be denoted as {Relevant} ∩ {Retrieved}. This can be shown in the form of a Venn diagram as follows:

a) Precision
Precision is the percentage of retrieved documents that are in fact relevant to the query. Precision can be defined as
Precision= |{Relevant} ∩ {Retrieved}| / |{Retrieved}|
b) Recall
The recall is the percentage of documents that are relevant to the query and were in fact retrieved. The recall is defined as
Recall = |{Relevant} ∩ {Retrieved}| / |{Relevant}|


Comments
Post a Comment