What are the key steps involved in the knowledge discovery process in database?
Knowledge Discovery in Database (KDD)
Knowledge discovery in databases (KDD) is the process of discovering useful knowledge from a collection of data.
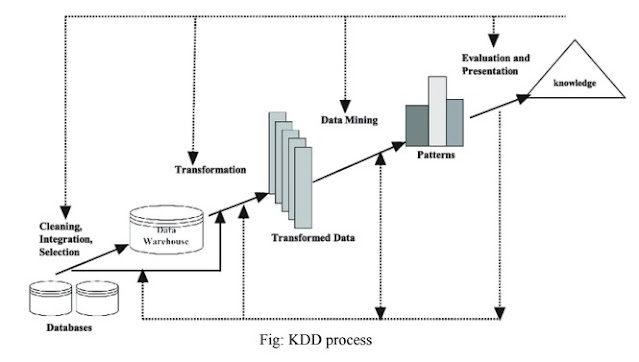
The steps involved in the knowledge discovery process:
Data Cleaning: data cleaning is a process of removing unnecessary and inconsistent data from the databases. The main purpose of cleaning is to improve the quality of the data by filling in the missing values, configuring the data to make sure that it is an inconsistent format.
Data Integration: In this step data from various sources such as databases, data warehouses, and transactional data are combined.
Data Selection: Data that is required for the data mining process can be extracted from multiple and heterogeneous data sources such as databases, files, etc. Data selection is a process where the appropriate data required for analysis is fetched from the databases.
Data Transformation:: In the transformation stage data extracted from multiple data sources are converted into an appropriate format for the data mining process. Data reduction or summarization is used to decrease the number of possible values of data without affecting the integrity of data.
Data Mining: It is the most essential step of the KDD process where intelligent methods are applied in order to extract hidden patterns from data stored in databases.
Pattern Evaluation: This step identifies the truly interesting patterns representing knowledge on the basis of some interestingness measures. Support and confidence are two widely used interesting measures. These patterns are helpful for decision support systems.
Knowledge Presentation: In this step, visualization and knowledge representation techniques are used to present mined knowledge to users. Visualizations can be in form of graphs, charts, or tables.
OR,
KDD includes multidisciplinary activities. This encompasses data storage and access, scaling algorithms to massive data sets, and interpreting results. The data cleansing and data access process included in data warehousing facilitate the KDD process. Artificial intelligence also supports KDD by discovering empirical laws from experimentation and observations. The patterns recognized in the data must be valid on new data and possess some degree of certainty. These patterns are considered new knowledge. Steps involved in the entire KDD process are:

.• Data Cleaning - In this step, the noise and inconsistent data are removed.
• Data Integration - In this step, multiple data sources are combined.
• Data Selection - In this step, data relevant to the analysis task are retrieved from the database.
• Data Transformation - In this step, data is transformed or consolidated into forms appropriate for mining by performing summary or aggregation operations.
• Data Mining - In this step, intelligent methods are applied in order to extract data patterns.
• Pattern Evaluation - In this step, data patterns are evaluated, or It identifies the truly interesting representing knowledge based on interesting measures.
• Knowledge Presentation - In this step, knowledge is represented or, where visualization and knowledge representation techniques are used to present mined knowledge to users.
Steps 1 through 4 is different forms of data preprocessing, where data are prepared for mining. The data mining step may interact with the user or a knowledge base. The interesting patterns are presented to the user and may be stored as new knowledge in the knowledge base.



Comments
Post a Comment