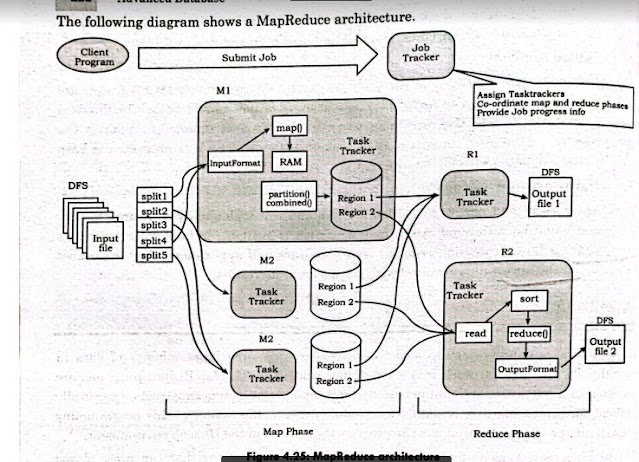
Define ODMG object model. What is object query language (OQL)?

ODMG object model It is an object data management Group, (ODMG) The ODMG object model is the data model upon which the object definition language (ODL) and object query language (OQL) are based. It is meant to provide a standard data model for object databases, just as SQL describes a standard data model for relational databases. It also provides a standard terminology in a field where the same terms were sometimes used to describe different concepts. Object query language (OQL) OQL is an SQL-like declarative language that provides a rich environment for efficient querying of database objects, including high-level primitives for object sets and structures. OQL also includes object extensions for object identity, complex objects, path expressions, operation invocation, and inheritance. OQL's queries can invoke operations in ODMG language bindings, and OQL may be embedded in an ODMG language binding. The object query language OQL is the query language p...




.png)