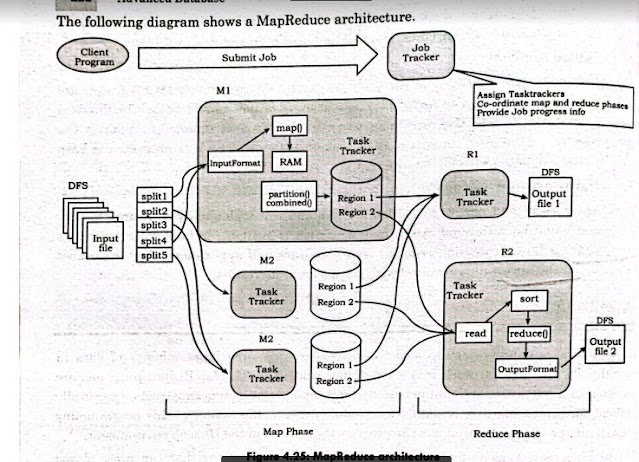
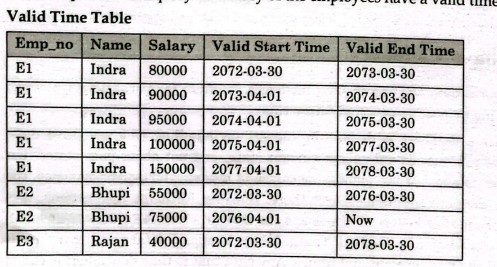
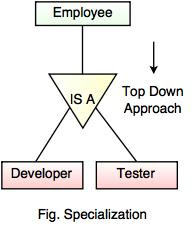
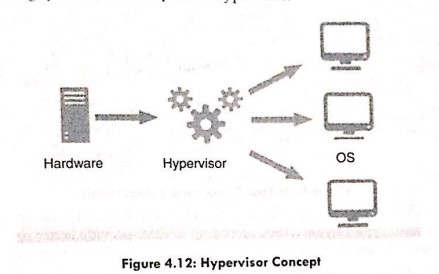
How thread is different from task? How thread programming is done?
.png)
Thread is different from the task in the following ways:- A t ask describes a program that may need input files and generate output files as a result of its execution and applications are a collection of tasks. Tasks are submitted for execution, and their Output data is gathered at the conclusion. The way tasks are produced, the sequence in which they are executed, and whether they need data interchange to distinguish the application models that come under the task programming umbrella. A Task may be used to indicate what you want to perform, and then that Task may be attached to a Thread. Threads are utilized to finish the task by splitting it up into pieces and executing them individually in a distributed system. A thread is a fundamental unit of CPU utilization that consists of a program counter, a stack, and a collection of registers. Threads have their program and memory areas. A thread of execution is the shortest series of programmed instructions th...
.png)


.gif)